AI inference engineering matures as open models drive 80% cost savings
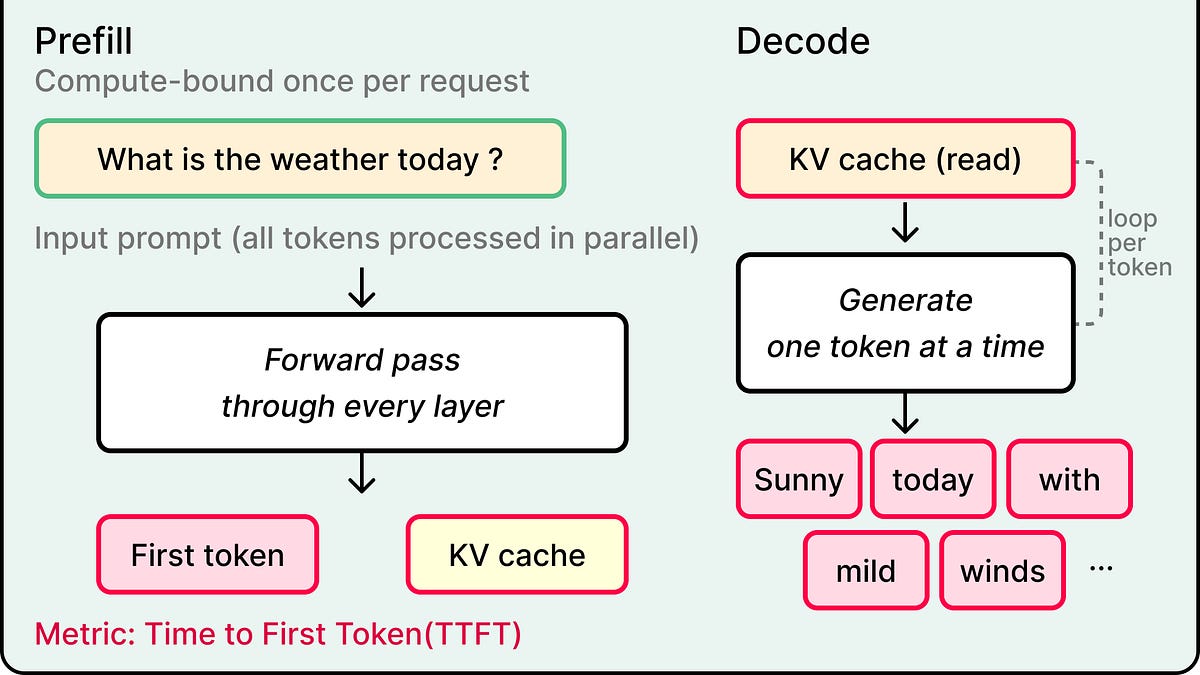
This article explains AI inference engineering, focusing on optimizing Large Language Model (LLM) operations in production for efficiency. It details techniques like batching, quantization, and disaggregation to improve latency, throughput, and cost, driven by the shift towards self-hosting open AI models. The piece highlights the importance of understanding the prefill-decode split in LLM inference for effective optimization.
Key Takeaways
- Hugging Face now hosts more than 2 million open models, a 25x increase over the last five years.
- The prefill phase is compute-bound and determines time-to-first-token (TTFT), while the decode phase is memory-bandwidth-bound.
- Quantization can reduce model weights from 16-bit to 4-bit, yielding 30-50% performance gains despite potential quality loss in attention layers.
- Disaggregation separates prefill and decode operations onto different hardware clusters to optimize independent traffic patterns.
- Self-hosted open models like DeepSeek V3 now rival closed models, offering four-nines uptime versus the two-nines typical of public APIs.
Why It Matters
Inference engineering has transitioned from a niche specialty within labs like Anthropic to a core competency for any enterprise scaling AI. By unbundling the compute and memory bottlenecks of the GPU, engineers can tune latency profiles that generic APIs cannot match. This shift creates a massive competitive advantage for companies that can effectively deploy techniques like speculative decoding and prefix caching. As the market moves toward 'agentic' workflows requiring long responses, the ability to minimize cost-per-token while maintaining high throughput will determine which platforms can profitably scale complex AI video and search features. Watch for further adoption of heterogeneous disaggregated compute stacks.
Additional Context
The transition toward custom inference stacks coincides with a significant surge in AI infrastructure capacity. Per The Information, June 2026, NVIDIA has increased its share of the AI inference chip market to 74%, up from 66% a year ago, despite growing competition from internal cloud-provider silicon. This dominance is bolstered by the Blackwell architecture, which according to NVIDIA's June 2026 reports, runs 20 times more AI agents per megawatt than the previous Hopper generation. This efficiency gain is critical for 'agentic' AI tools, which place unique sequential demands on hardware during the prolonged decode phase of long-horizon tasks. Simultaneously, the open-source ecosystem is reaching a new level of density. As of May 2026, external monitoring of the Hugging Face Hub recorded over 2.88 million public models, with new repositories being added at a rate of approximately 89,000 per month. This volume is increasingly dominated by Chinese model families like DeepSeek, which per ResearchGate, June 2026, utilize architectures such as Multi-head Latent Attention (MLA) to activate only 37 billion parameters of a 671-billion-parameter model during inference, dramatically lowering the hardware bar for self-hosting frontier-class intelligence. Competitive pressure is also mounting from hardware startups targeting the disaggregated inference market. d-Matrix announced in June 2026 that its Corsair platform is in full production, claiming it treats prefill and decode as heterogeneous tasks to deliver a 10x speed-up over GPU-only clusters. Meanwhile, Tensordyne reported a successful tape-out of its Napier system in June 2026, promising 13x higher throughput than Blackwell systems. These developments suggest a future where the AI engineering stack is defined by specialized silicon rather than general-purpose compute.
Read full article at blog.bytebytego.com